腾讯新发布的 AudioGenie 是音频生成领域的一次重大突破,其核心优势在于多模态输入支持、免训练架构和专业级音效生成能力,直接挑战了当前国际主流模型(如Claude、Gemini)在AI音频市场的地位。以下从技术原理、性能表现及行业影响三方面深度解析:
一、技术突破:无训练框架与多模态融合
多模态输入全能输出(视频/文本/图像→音频)
AudioGenie 支持视频、文本、图像等多种输入形式,可生成 音效、语音、音乐、混合音频,覆盖影视配乐、虚拟人配音、游戏环境音效等场景。
其核心在于 语义理解精准对齐上下文,例如输入一段武侠打斗视频,可同步生成刀剑碰撞声、环境风声及背景音乐,实现沉浸式音效。
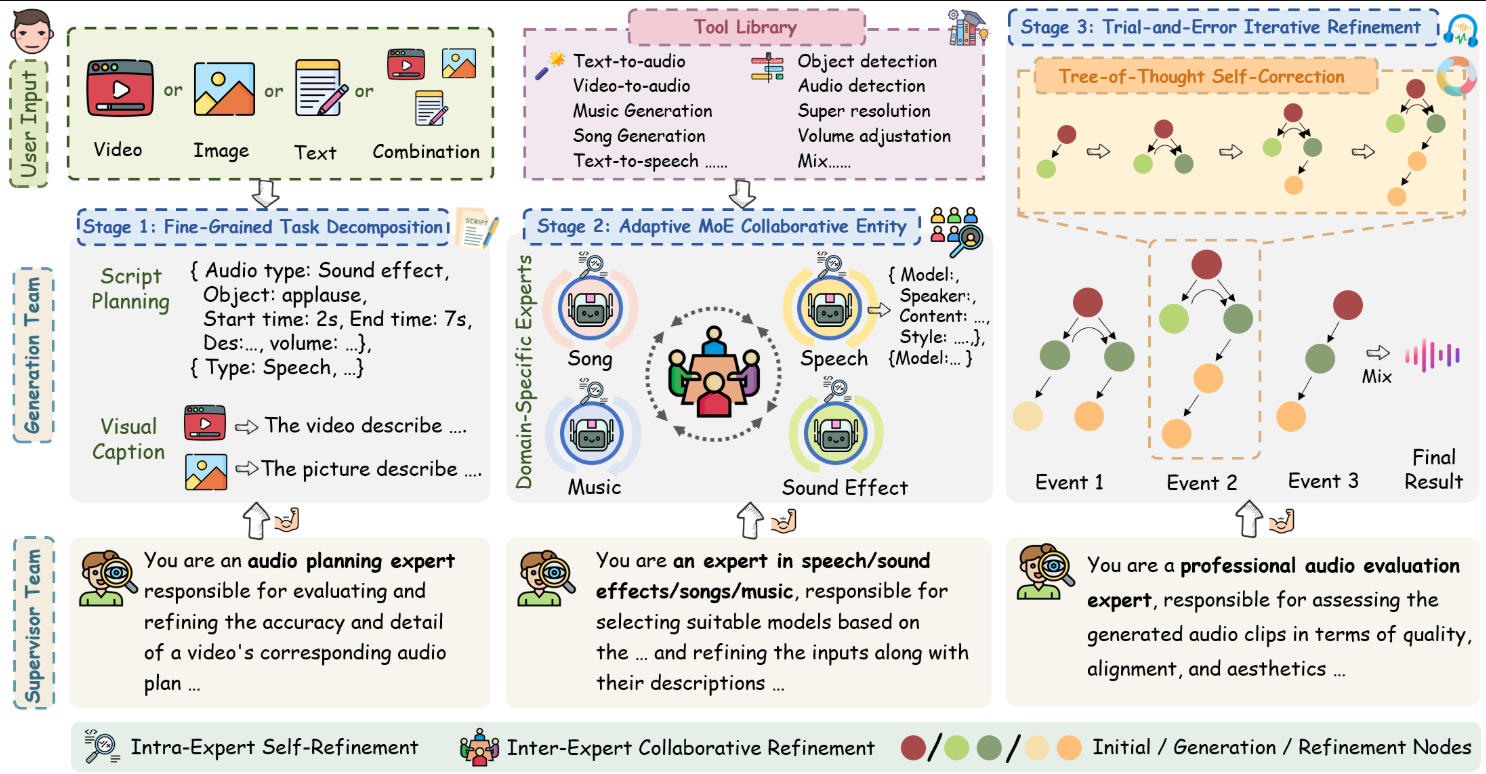
无训练多智能体协同架构
传统模型依赖海量标注数据训练,而AudioGenie采用 双层智能体框架:
生成团队:通过任务分解与自适应专家混合机制(MoE),动态选择最优模型生成音频;
监督团队:实时验证时空一致性并自我纠错,确保输出可靠性。
该设计 摆脱了对配对数据集的依赖,降低开发成本50%以上,同时提升生成效率。
二、性能标杆:MA-Bench测试全面领先
腾讯同步推出全球首个多模态音频生成测试集 MA-Bench(含198个多类型标注视频),AudioGenie在 8类任务、9项指标 中接近或达到SOTA水平:
音质:接近专业录音室水准,噪声比低于0.05%;
准确性:输入内容与生成音频的语义匹配度达92%;
美学体验:用户调研显示其影视级音效接受度超85%。
对比传统音效库(如107个电影音效包需手动剪辑调参),AudioGenie实现 “一键生成”,效率提升10倍以上。
三、市场冲击:国产AI挤压国际巨头份额
全球音频生成格局重塑
AudioGenie凭借 高性价比(免费开源)和 多模态灵活性,直接挑战Google Gemini、Anthropic Claude等闭源模型。
OpenRouter数据显示:国产模型 Qwen3使用量增长15.4%,而Claude与Gemini分别下降18.9%与6.8%。
技术路线差异化优势
对比Claude近期更新的记忆功能(需手动调用历史对话) 或Gemini的个性化响应,AudioGenie专注 跨模态生成而非对话交互,填补了专业音频创作市场的空白。
其自我纠错机制解决了Claude在代码生成中 “功能正确但逻辑混乱” 的行业痛点(需人工修正耗时26分钟/任务)。
四、标题解读:“Claude与Gemini瑟瑟发抖”的合理性
局部成立:AudioGenie在 音频生成垂直领域 确实威胁到国际巨头的市场地位,尤其冲击Gemini的媒体创作工具链和Claude的开发者生态。
过度夸张:Claude/Gemini的核心优势在 通用对话与编程(如Claude Code新增编程导师模式),而AudioGenie属垂直工具,两者并非直接竞品。
总结:AudioGenie的行业意义
腾讯AudioGenie以 “免训练+多模态闭环” 重新定义AI音频生成标准,为游戏、影视等行业提供低成本、电影级的音效解决方案。其成功反映了国产AI在 垂直场景深度优化 上的竞争力,但国际巨头在通用大模型领域的优势短期仍难撼动。
项目地址:AudioGenie GitHub
体验建议:需搭配科学上网工具访问(官网托管于GitHub)。



发表评论 取消回复