NVIDIA 发布的 Jet-Nemotron 模型系列(包括 2B 和 4B 参数版本),通过在架构和效率上的创新,确实实现了显著的性能提升和成本节约。
核心创新:PostNAS 与 JetBlock
Jet-Nemotron 的性能飞跃主要得益于两项核心技术创新:
后神经架构搜索 (PostNAS):这是一种高效的模型架构改造流程。它并非从零开始训练新模型,而是:
冻结知识:选择一个现有的、预训练好的高性能全注意力模型(如 Qwen2.5),并冻结其 MLP(多层感知机)层的权重,以保留模型已学到的知识和能力,大幅降低训练成本。
精准替换:将原模型中计算密集的全注意力机制替换为高效的线性注意力模块 JetBlock。
混合架构与硬件感知:通过超级网络训练和集束搜索,自动确定全注意力层和线性注意力层的最佳组合与位置,在保证关键任务(如数学、代码、常识推理、检索)精度的同时,最大化目标硬件(如 NVIDIA H100 GPU)上的吞吐量。
新型线性注意力模块 (JetBlock):JetBlock 是 NVIDIA 设计的硬件高效线性注意力模块。
它引入了输入条件化的动态因果卷积核,可根据输入内容动态调整,优于此前线性注意力模块中常用的静态卷积核。
它移除了在查询(Q)和键(K)上的冗余静态卷积,简化了计算流程。
通过硬件感知的架构搜索,JetBlock 在提升吞吐量的同时,还实现了准确率的提升。
主要优势
Jet-Nemotron 带来的好处是多方位的:
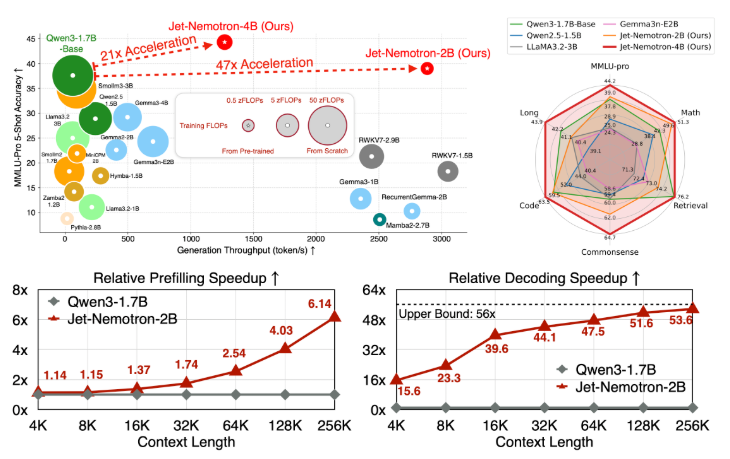
极高的推理效率与极低的成本:如上表所示,其吞吐量提升数十倍,KV 缓存显著缩小,直接 translates to 98% 的推理成本降低。这使得大规模部署高质量大语言模型变得非常经济。
出色的精度保持甚至超越:Jet-Nemotron 在数学、代码、常识推理、检索和长上下文理解等多个关键基准测试中,准确率均达到或超过了同规模甚至更大参数规模的先进全注意力模型(如 Qwen3-1.7B-Base)。
设备端部署成为可能:极小的 KV 缓存(如 Jet-Nemotron-2B 仅需 154MB)和高效的计算,使得在 Jetson Orin、RTX 3090 等边缘设备和终端设备上运行 SOTA 大语言模型成为现实,无需依赖云端。
推动架构创新与快速迭代:PostNAS 提供了一个低成本、低风险的架构探索平台。研究人员可以快速验证新注意力机制的有效性,而无需投入巨资进行完整的预训练,这有望加速大语言模型架构的演进。
应用影响
对企业而言,大规模提供高质量、低延迟的AI服务(如实时文档分析、长上下文交互、智能编程辅助)的成本门槛将大幅降低。
对开发者和研究者而言,可以更轻松、更廉价地获取和利用高性能大语言模型,专注于应用创新而非底层基础设施的局限。
对边缘计算而言,强大的AI能力得以延伸至网络边缘,支持更智能的物联网设备、机器人和其他离线应用。
注意事项
Jet-Nemotron 的代码和模型计划在 GitHub 上开源(截至2025年8月26日的信息,仍在等待法律合规审核)。因此,实际的体验和部署可能需要关注其官方开源进度的释放。
总结一下
NVIDIA 的 Jet-Nemotron 通过 PostNAS 这一创新的“改造”流程和 JetBlock 这一高效的线性注意力模块,在几乎不牺牲精度的情况下,实现了推理速度的数十倍提升和成本的大幅下降。这不仅是技术上的突破,更可能降低高质量大语言模型的应用门槛,推动AI在更广阔场景的落地。
希望这些信息能帮助你全面了解 Jet-Nemotron。如果你想深入技术细节,可以查阅其论文或关注其官方 GitHub 仓库的更新。
发表评论 取消回复