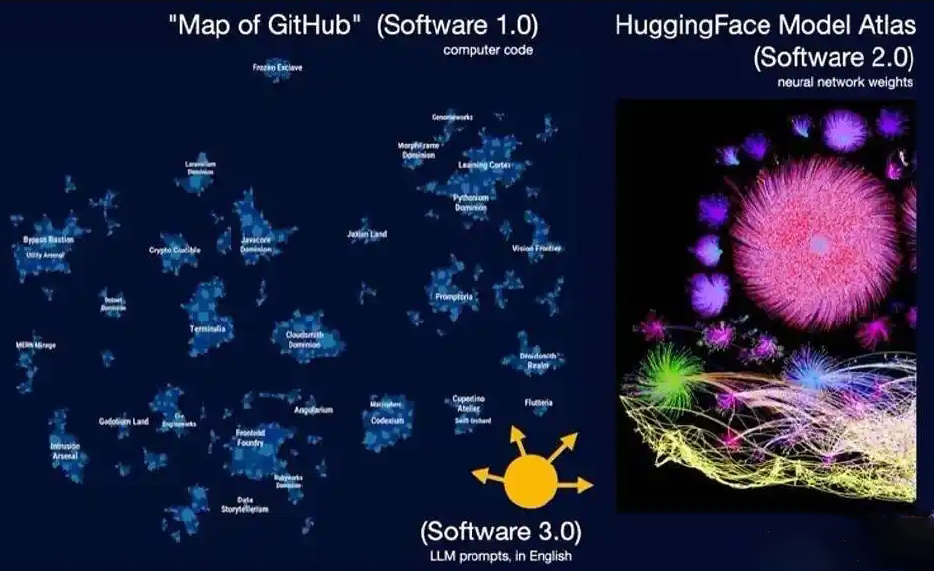
一、软件演进的三个阶段
软件1.0(代码驱动)
核心:人类直接编写确定性指令(如Python/C++),逻辑显式定义。
代表平台:GitHub作为代码托管生态。
软件2.0(权重驱动)
核心:通过数据集训练神经网络生成权重参数,程序由优化器“学习”而非手动编写。
代表平台:Hugging Face成为“模型界的GitHub”,例如Stable Diffusion的LoRA微调即等效于一次“Git提交”。
软件3.0(提示词驱动)
核心:自然语言(如英语)提示词(Prompt)成为新编程语言,直接调度大模型(LLM)完成任务。
案例对比:
情感分析任务:
软件1.0需手写规则代码;
软件2.0需标注数据集训练分类器;
软件3.0仅需自然语言指令+示例。
意义:编程门槛大幅降低,非技术用户可通过语言描述创造软件。
二、LLM的三重本质属性
公共事业属性(Utility)
OpenAI等公司以CAPEX训练基础模型(类比电网建设),通过API提供OPEX服务(按Token计费)。
依赖症凸显:顶级LLM宕机即引发全球“智能停电”。
晶圆厂属性(Fab)
训练需巨额资本与尖端技术,分化为两种模式:
无晶圆厂模式:依赖NVIDIA GPU;
垂直整合模式:如Google自研TPU。
操作系统属性(OS)
架构类比:LLM=CPU,上下文窗口=内存,提示词=命令行输入。
生态现状:
闭源巨头(GPT/Gemini)类似Windows/macOS;
开源社区(LLaMA)类似Linux。
时代定位:处于“1960年代分时计算”阶段——算力集中云端,个人设备(如Mac Mini运行小模型)是革命前兆。

三、LLM的能力与缺陷:“有缺陷的超人”
超能力:
百科全书式记忆(如背诵Git哈希值)。
致命缺陷:
幻觉与低级错误:如判断“9.11 > 9.9”或数错字母;
锯齿状智力:部分任务超越人类,却犯人类不会犯的错;
顺行性失忆:无长期记忆,上下文窗口清空即遗忘(类比《记忆碎片》)。
四、核心机遇:半自主化AI产品
核心理念:不造“钢铁侠”(全自主AI),而是造“钢铁侠战衣”(人机协同)。
关键设计:
自主性滑块:用户控制AI参与程度,例如:
编程工具Cursor:从代码补全到全库重构的多级控制;
搜索工具Perplexity:自主性可调的研究模式。
Vibe Coding实践:Karpathy本人用英语提示词一天开发iOS应用,但部署(支付/认证)仍依赖人工点击——揭示当前基础设施局限。

五、未来基础设施:为AI智能体重构世界
现存问题:当前网站/文档为人类设计(如“点击这里”),AI无法解析。
解决方案:
LLM.txt协议:类似robots.txt,声明网站对AI的开放规则;
机器友好接口:如Vercel/Stripe提供Markdown文档,用curl命令替代图形界面操作;
智能体优先设计:打通系统孤岛,使AI可跨平台调度工具(例:实在Agent自动处理Excel→CRM同步)。
六、技术演进三阶段展望
短期:软件重构为“人类+大模型”协同模式,半自主应用爆发;
中期:大模型渗透企业工作流,代码/文档/数据分析全面智能化;
长期:贾维斯级助手普及,但人类保持最终决策权(自主性滑块右移不失控)。
💡 演讲总结:Karpathy呼吁开发者掌握三种范式技能(1.0代码/2.0训练/3.0提示词),并强调“2025是Agent的十年”——其本质是重建人机协作范式,而非追求完全自动化。软件3.0时代的标志是:自然语言成为创世工具,人类从“程序员”转型为“AI教师”。

发表评论 取消回复