夸克发布的健康大模型技术报告,详细揭示了其AI“主任医师”背后的技术细节。这不仅是技术能力的展示,更体现了AI在医疗健康领域深度工程化应用的探索。下面我将为你梳理其核心要点。
一、核心成就与定位
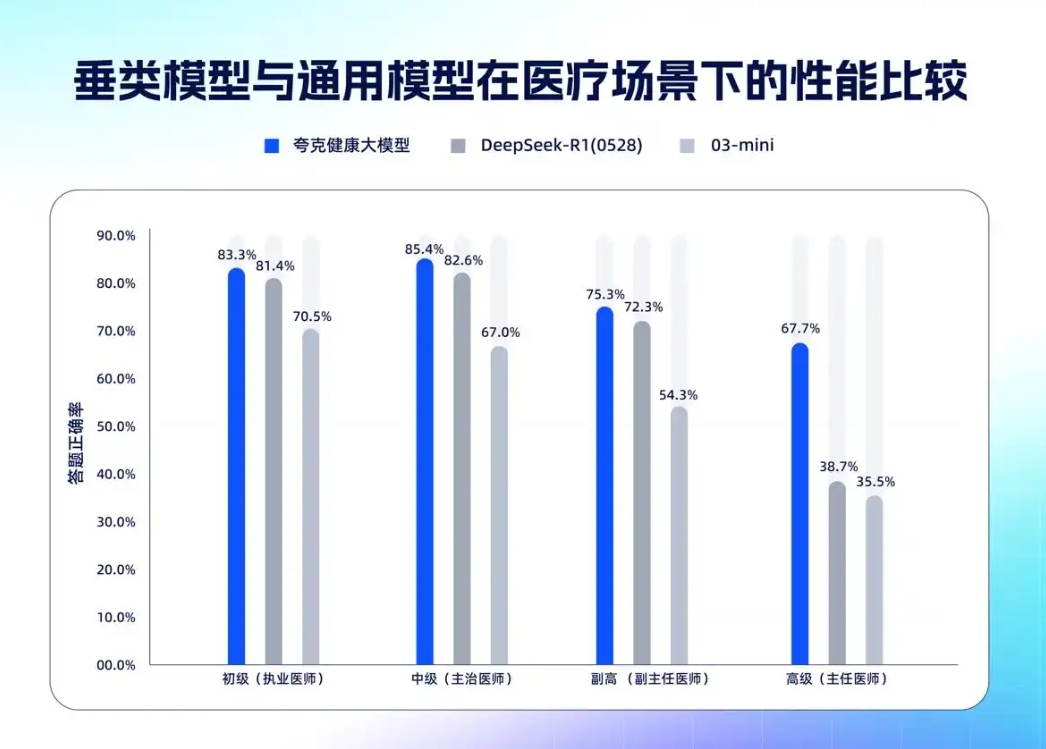
国内首个通过12门核心学科主任医师笔试评测的AI模型:夸克健康大模型(QuarkMed)在2025年7月成功通过了涵盖全科医学等12门核心学科的主任医师笔试评测。这标志着其医学专业能力达到了一个全新的水准。
“难度越高,领先优势越明显”:与通用大模型相比,QuarkMed在处理复杂医学推理任务时优势更为突出,呈现出“难度越高,领先优势越明显”的性能曲线。这意味着它在解决需要深度思考和专业判断的医疗问题时表现更为出色。
已集成至夸克AI搜索投入实用:用户在日常健康咨询时,通过夸克APP的“深度搜索”功能就能调用这位“主任级AI医生”的能力。

二、核心技术突破:慢思考与深度工程化
夸克健康大模型并非简单地堆砌医学知识,其核心突破在于让AI学会了“医学思维”,即模拟人类医生严谨、渐进式的临床推理过程。这主要通过以下几项关键技术实现:
| 技术组件 | 功能描述 | 实现价值/突破 |
|---|---|---|
| 慢思考能力 | 融合了链式推理(Chain-of-Thought) 与多阶段临床演绎路径建模,驱动模型分阶段、层层深入地推导复杂医疗问题。 | 使AI的推理过程更接近人类专家的临床思维,处理复杂病例时更可靠,输出结果具有更高的可解释性。 |
| “双数据产线”工程体系 | 将医学数据划分为 “可验证” (如诊断结论、药物查询)和 “不可验证” (如健康建议、心理支持)两类,并分别设计数据构建与评估 pipeline。 | 针对不同医学任务特性精细化处理数据,确保诊断类任务的准确性和健康建议类任务的合理性、安全性及人性化。 |
| “双奖励机制”训练系统 | 引入 “过程奖励模型” (评估推理链的合理性)和 “结果奖励模型” (评估最终结论的准确性)共同指导模型优化。 | 显著提升模型的临床可解释性和推理一致性,确保AI不仅“答得对”,而且“思考过程”也符合医学逻辑。 |
| 多阶段强化学习(RL) | 包含两个关键RL阶段:一阶段专注于提升复杂场景中的医学推理能力;二阶段通过奖励模型从诚实性、有用性、内容合规性角度调整模型行为。 | 系统性提升模型的正确性、安全性以及符合人类偏好和价值观的能力,使其输出更可靠、更负责任。 |
| 高质量数据体系 | 模型训练使用了三类核心医疗数据:医学资料、医学知识和医疗记录,数据总量高达约1万亿Token。 | 有效弥补预训练语料库的不足,为模型提供了丰富、专业的学习材料,是其准确性与强大推理能力的基础。 |
| 专业医师深度赋能 | 拥有千人规模的专业医师标注团队,其中超过400名为副主任医师及以上的高资历医疗专家,构建了十几万条精标样本数据。 | 极大保障了核心训练数据(特别是冷启动数据)的专业性和权威性,将顶尖医生的临床思维和经验“注入”AI模型。 |
三、性能表现与实际应用
权威评测结果:
在中国医师资格考试(CPQExam)笔试评测中,其表现出了“难度越高,领先优势越明显”的特点。
在MedQA等多个国际权威数据集测试中,夸克健康大模型相比同等规模的通用模型(如o3-mini)也表现出了更优异的性能。
具体业务指标显示,在有检验检查的疾病上,模型回答准确率已达90.78%,接近专科医生水平;在疑难疾病上,准确率达到85.51%。
真实世界应用反馈:
许多医学生和医生群体都在使用它辅助学习、备考和临床参考。
据报道,夸克AI搜索在全国医学生中的月活用户已突破200万,覆盖率过半。
北京大学人民医院皮肤科主任医师李厚敏和武汉大学人民医院精神卫生中心主任王惠玲等专家在试用后,对其在治疗方案合理性、用药规范性、疾病长期管理乃至患者心理疏导方面给出的全面建议给予了高度评价。
四、未来展望与开放精神
夸克在技术报告中透露,计划将其医师考试测试集全面公开。这一举措将有助于促进整个医学AI研究社区的共同发展和进步。
总结
夸克健康大模型技术报告的发布,不仅展示了其AI“主任医师”的实力,更重要的是,它为高性能、高可靠性的医疗垂直大模型研发提供了一套经过实践验证的工程化范例:以慢思考推理为核心,以深度工程化的数据产线和训练系统为支撑,并以资深医学专家的深度标注与反馈为保障。
这意味着AI在医疗领域的应用,正在从简单的信息问答,迈向能够提供深度、可靠、可信赖的智能辅助新阶段。这对于缓解医疗资源压力、提升基层医疗水平、辅助医生诊断和患者教育都具有积极的意义。
如果你想深入了解技术细节,可以查阅夸克发布在arXiv和GitHub上的完整技术报告《QuarkMed Technical Report》。
发表评论 取消回复